Anasayfa
Anasayfa Canlı Borsa
Canlı Borsa Borsa
Borsa Döviz Kurları
Döviz Kurları Altın
Altın Hisse Senetleri
Hisse Senetleri Endeksler
Endeksler Kripto Paralar
Kripto Paralar Döviz Hesaplama
Döviz Hesaplama Döviz Çevirici
Döviz Çevirici Kredi Arama
Kredi Arama
Dijital bilgi erişim sistemleri, 2026 yılı itibarıyla geleneksel arama motoru dizinlerinden, karmaşık dil modellerinin (LLM) anlık yanıt mekanizmalarına doğru evrilmiştir. İnternet kullanıcılarının bilgiye ulaşma yöntemlerindeki bu yapısal değişiklik, dijital varlıkların ve markaların internet üzerindeki konumlanma biçimlerini de doğrudan etkilemektedir. Kredi Kredi olarak, finansal teknolojiler ve dijital trendler üzerine yaptığımız incelemeler kapsamında, ChatGPT ve benzeri yapay zeka sistemlerinin sonuç sayfalarında (SERP yerine AIGS – AI Generated Answers) yer alma dinamiklerini teknik bir perspektifle ele alıyoruz.
Bu analiz, mevcut algoritmaların çalışma prensiplerini ve görünürlük üzerindeki belirleyici faktörleri, herhangi bir yönlendirme yapmaksızın, tamamen durum tespiti niteliğinde sunmaktadır.
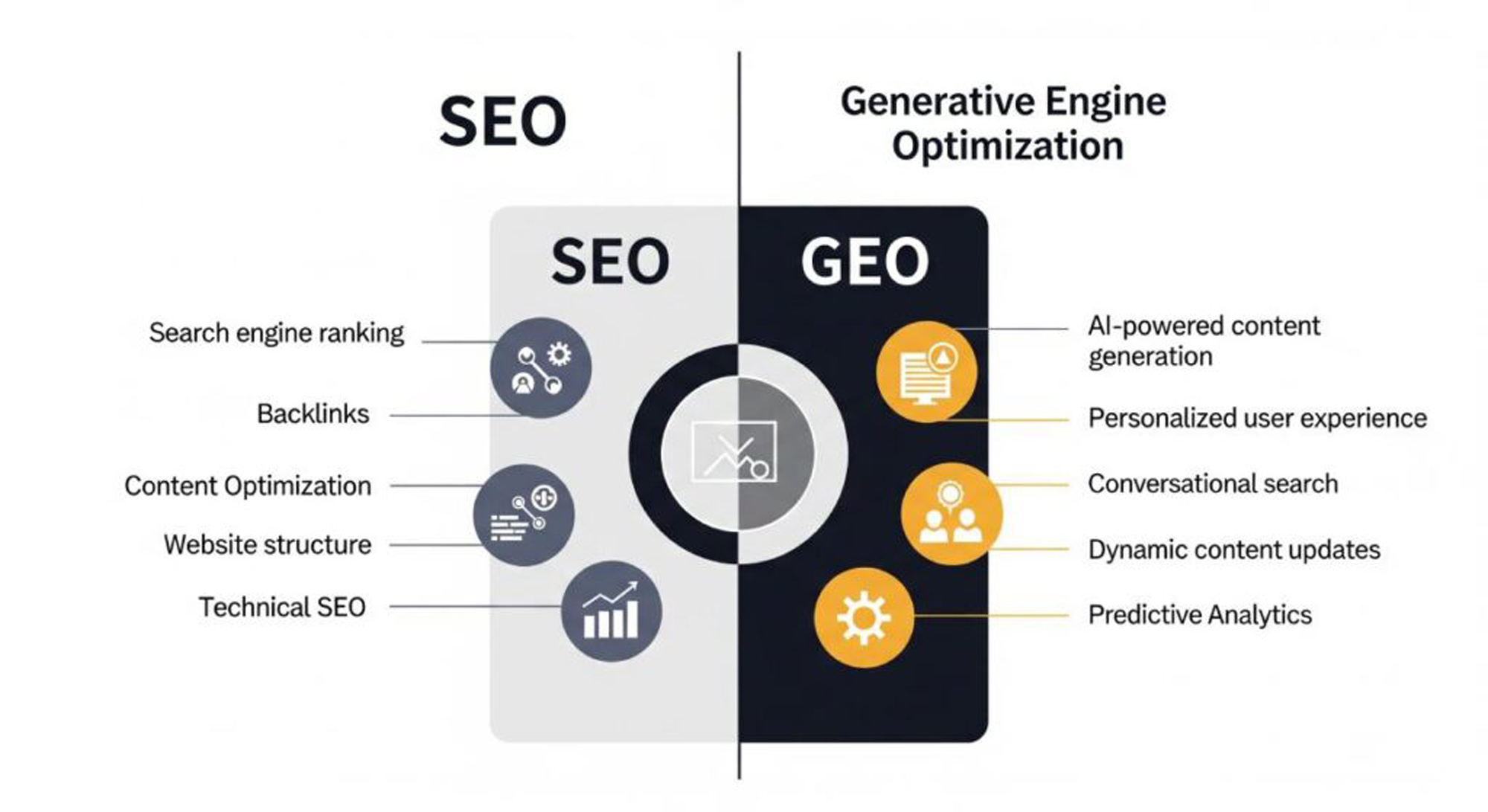
Arama Motoru Optimizasyonundan Üretken Motor Optimizasyonuna Geçiş
Geçmiş yıllarda “Arama Motoru Optimizasyonu” (SEO) olarak tanımlanan süreçler, web sitelerinin belirli anahtar kelimelerle arama motoru sıralamalarında üstlerde yer almasını hedeflemekteydi. Ancak 2026 yılı dijital ekosisteminde bu kavram, yerini büyük ölçüde “Üretken Motor Optimizasyonu” (GEO – Generative Engine Optimization) kavramına bırakmış durumdadır. ChatGPT gibi sistemler, kullanıcının sorusuna yanıt verirken web sitelerini birer bağlantı olarak listelemek yerine, bu kaynaklardan elde ettiği bilgileri sentezleyerek doğrudan, konuşma diline yakın bir metin oluşturmaktadır.
Bu yeni düzende, bir içeriğin yapay zeka tarafından kaynak olarak kabul edilmesi, sadece anahtar kelime eşleşmesine değil, anlamsal bütünlüğe ve bağlamsal ilişkilere dayanmaktadır. Algoritmaların, bilgiyi sadece taramadığı, aynı zamanda “anladığı” ve “yorumladığı” bir süreç işlemektedir. Dolayısıyla, arama sonuçlarında yer alma durumu, bir sıralama yarışından ziyade, yapay zeka modelinin oluşturduğu cevabın bir parçası olma durumuna dönüşmektedir.
Bilgi Otoritesi ve Doğrulanabilir Kaynak Yapısı
Yapay zeka modellerinin, özellikle finans, sağlık ve hukuk gibi hassas kategorilerde (YMYL – Your Money Your Life) içerik üretirken, “halüsinasyon” olarak adlandırılan yanlış bilgi üretme riskinden kaçındığı gözlemlenmektedir. Bu nedenle, modellerin veri setlerinde “otoriter” olarak etiketlenen kaynaklara öncelik verildiği teknik analizlerde görülmektedir. Bir markanın veya web sitesinin ChatGPT sonuçlarında referans gösterilmesi, genellikle o kaynağın dijital dünyadaki güvenilirlik skoru ile paralellik göstermektedir.
Güvenilirlik, sadece site içi faktörlerle değil, site dışı sinyallerle de ölçülmektedir. Akademik makaleler, ulusal haber kaynakları, sektörel raporlar ve bağımsız inceleme platformlarında yer alan atıflar, yapay zeka için birer doğrulama sinyali işlevi görmektedir. Modelin eğitim verisinde veya anlık internet taramasında (browsing), bir marka hakkında tutarlı ve doğrulanmış bilgilerin bulunması, o markanın yanıt metinlerine dahil edilme olasılığını artıran temel faktörlerden biri olarak öne çıkmaktadır.
Semantik İlişkilendirme ve Vektörel Veri Uyumu
Büyük Dil Modelleri, kelimeleri ve kavramları matematiksel vektörler olarak işlemektedir. Bu sistemde, birbirine anlamsal olarak yakın olan kavramlar eşleştirilmektedir. 2026 yılı algoritmalarında, içeriğin sadece ne hakkında olduğu değil, o konuyu ne kadar derinlemesine ve kapsamlı ele aldığı analiz edilmektedir. Sığ, yüzeysel veya sadece trafik çekme amacı taşıyan içeriklerin, yapay zeka tarafından filtrelendiği ve yanıt oluşturma sürecine dahil edilmediği görülmektedir.
İçeriklerin teknik yapısında, yapılandırılmış veri (schema markup) kullanımının, botların içeriği anlamlandırmasını kolaylaştırdığı bilinmektedir. Özellikle soru-cevap formatındaki net, veriye dayalı ve istatistiklerle desteklenmiş paragraflar, yapay zekanın kullanıcı sorularına vereceği doğrudan yanıtlar için hazır birer yapı taşı niteliği taşımaktadır. Bilginin muğlak ifadeler yerine, kesin ve sayısal verilerle sunulması, makine öğrenimi modellerinin veriyi işleme sürecini hızlandıran unsurlar arasında yer almaktadır.

Marka Varlığının Bilgi Grafiğindeki Yeri
Google ve OpenAI gibi teknoloji devlerinin geliştirdiği bilgi grafikleri (Knowledge Graph), varlıklar (entity) arasındaki ilişkileri haritalandırmaktadır. Bir markanın ChatGPT sonuçlarında yer alması, sistemin o markayı tanınmış bir “varlık” olarak kabul etmesine bağlıdır. Bu kabul süreci, markanın isminin internet genelinde ne sıklıkla, hangi bağlamda ve hangi sıfatlarla birlikte geçtiği ile şekillenmektedir.
İnternet üzerindeki dijital ayak izi, markanın sektörel konumunu belirlemektedir. Örneğin, “kredi kartı kampanyaları” konusunda bir sorgu yapıldığında, sistemin hangi bankayı veya finans kuruluşunu önereceği, o kuruluşun internetteki güncel kampanyalarla ne kadar güçlü bir şekilde ilişkilendirildiğine dayanmaktadır. Bu ilişkilendirme, markanın kendi web sitesindeki beyanlardan ziyade, üçüncü taraf kaynakların marka hakkında ürettiği içeriklerle sağlanmaktadır.
Duygu Analizi ve Dijital İtibarın Algoritmik Yansıması
Yapay zeka modelleri, kullanıcı deneyimini iyileştirmek adına, genellikle pozitif veya nötr duygu durumuna sahip varlıkları öne çıkarma eğilimindedir. İnternet üzerindeki kullanıcı yorumları, şikayet platformları, forum tartışmaları ve sosyal medya etkileşimleri üzerinde yapılan “Sentiment Analysis” (Duygu Analizi), bir markanın yapay zeka gözündeki algısını oluşturmaktadır.
Analizler, hakkında yoğun olumsuz veri girişi bulunan veya güvenilirlik sorunu yaşayan markaların, yapay zeka tarafından “tavsiye edilenler” listesinden çıkarıldığını göstermektedir. Buna karşılık, müşteri memnuniyeti yüksek, şeffaf ve erişilebilir olduğu bağımsız kaynaklarca teyit edilen organizasyonların, jeneratif yanıtlarda daha sık yer bulduğu tespit edilmiştir. Dolayısıyla dijital itibar yönetimi, sadece bir halkla ilişkiler konusu olmaktan çıkıp, algoritmik bir görünürlük parametresine dönüşmüş durumdadır.
Teknik Erişilebilirlik ve Tarama Bütçesi
Yapay zeka botlarının (örneğin GPTBot) web sitelerini tarayabilmesi ve içeriği dizine ekleyebilmesi, görünürlüğün teknik ön koşuludur. Robots.txt dosyaları ve sunucu yanıt süreleri gibi teknik altyapı unsurları, botların siteye erişimini belirlemektedir. 2026 standartlarında, içeriğin sadece insanlar için değil, makineler için de okunabilir olması gerekliliği, teknik SEO çalışmalarının merkezinde yer almaktadır.
JavaScript tabanlı karmaşık yapıların yerine, metin odaklı ve hiyerarşik HTML yapılarının, yapay zeka botları tarafından daha hızlı ve hatasız işlendiği gözlemlenmektedir. Sitenin güncelliği, son eklenen verilerin zaman damgası ve içeriğin revize edilme sıklığı, modelin “güncel bilgi” arayışında tercih sebeplerini oluşturmaktadır.
2026 yılı itibarıyla dijital görünürlük, geleneksel sıralama faktörlerinden çok daha karmaşık ve çok katmanlı bir yapıya bürünmüştür. ChatGPT ve türevi yapay zeka sistemlerinin sonuçlarında yer almak; teknik altyapının uygunluğu, anlamsal içerik derinliği, dijital otorite ve çevrimiçi itibarın toplam bir bileşkesi olarak ortaya çıkmaktadır. Kredi Kredi olarak sunduğumuz bu analiz, dijital ekosistemin mevcut durumunu yansıtmakta olup, algoritmaların sürekli değişen doğasının ve yapay zeka teknolojilerindeki gelişmelerin, bu dinamikleri gelecekte de şekillendirmeye devam edeceği öngörülmektedir. Görünürlük, tek bir hamleyle değil, bütüncül bir dijital varlık yönetimiyle elde edilen bir sonuç olarak değerlendirilmektedir.